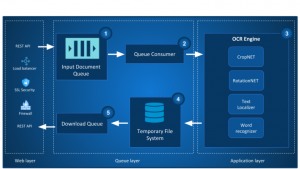
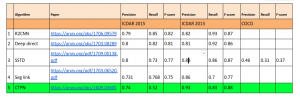
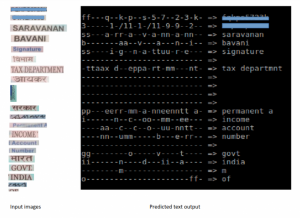
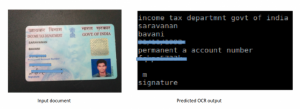
Introduction
The banking industry has always tried to stay ahead of the curve in being adaptive to modernization. It was one of the early adopters in the age of information and understood how much technology would incurve into people’s lives. This has enabled its growth as a pioneer and led it to become one of the largest consumers of Information Technology. Automation and AI are the next logical steps.
Automation in banking is the system of utilizing technology to operate banking processes through highly automatic means rendering human intervention to a minimum.
Gartner reported that the estimated expense on IT applications in the banking sector was $487 Billion in 2018. Lion’s share of this expense was for outsourced external companies which primarily constituted Business Process Outsourcing(BPO) companies. This added up to an approximate of $63 Billion being paid to these BPOs. Such precedent expenses can be avoided by evolving with the technology and the easiest way to minimize it is automation.
How has Automation Evolved Through the Ages?
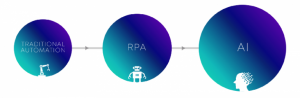
Traditional Automation
Traditional Automation permits and processes machinery to perform tasks. It uses primarily APIs and other methods to integrate systems and developers must be well versed in the functionality of the target system. This may include steps in operational processes and methods.
Traditional automation is limited in some aspects as in application customization due to insufficient software source code. It is also affected by the limitations of APIs. Most of its methods are rather primitive for today’s digital transformation. Nonetheless, it is still prevalent in many places.
RPA
Robotic Process Automation(RPA) focuses on front-end activities and doesn’t need any shifts for backend operations as RPA works across different applications. RPA bots function at UI(User Interface) level and within the system like humans and provide better personalization and easy customization than traditional automation for users.
Some major features of RPA include:
- Reliance on easy to program functionality with reduced TAT
- Bots execute individual functions- email responses,data extraction,etc.
- Works from UI comprehending user actions.
It’s used for data collation, analysis, invoicing, email management, and other customer service functions. Implementing RPA will cut costs for banks on many levels of these spheres as RPA & traditional automation relieve Individuals from tedious tasks.
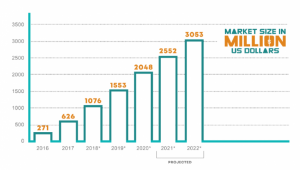
RPA- Market Revenues Worldwide (2016–2022)-Statista– Source
We must understand that RPA doesn’t replace any existing technology but works in tandem with the prevalent framework. In a nutshell, RPA handles repetitive, rule-based, and monotonous tasks and actions.
A common example of an RPA bot is the ubiquitous Chatbot. As RPA doesn’t have any AI involved, its scope to improve is limited. It doesn’t learn but helps the user. Here we discuss primarily RPA applications and Implementations.
Artificial intelligence
Artificial Intelligence is the latest technology for automation and mimics basic human intelligence, further advancing it. Such AI-enabled systems comprehend, evaluate, and respond to complex problems and situations efficiently by using Machine Learning algorithms. Some good examples of AI applications are NLP (Natural language processing) powered voice assistants such as Alexa, Google Assistant, and Siri.
Approximately 32% of service providers in the industry use AI technology to better customer experience and ease processing. They use technology like voice recognition, analytics, etc. This was reported in a joint research by Narrative Science and National Business Research Institute.
AI has expanded to such an extent that all the previous technologies used now fall under its own umbrella. Even then AI is met with some skepticism as it will completely take over the processing procedures and traditionalists may raise questions on dependability.
What Benefits Does Automation Offer that Makes Banking Better?
Automation provides the process of banking with versatile features that makes the entire procedure easier for banks and customers. Not only does it bring the safety and privacy of the customers to a higher standard, but also does it provide them with a fulfilling experience. Some of the features include:
- Better Customer Service- Data management becomes easier with RPA implementation. These include Daily inquiries, information transfer, application status, balance information, and others. This will free employee time for more critical decisions and tasks. An example is the functionality of a Chatbot which saves every involved party’s time.
- Improved Compliance- Banks are regulated by legislatures and other government bodies that prescribe many strict compliance guidelines. Accenture conducted a survey in 2016 in which 73% of respondents expected RPA to be a key enabler in compliance. This was because it increased productivity by being available 24 hours a day with immense accuracy.
- Accounts Payable- It requires vendor information extraction, validation, and payment processing. OCR(Optical Character Recognition) technology is used to obtain data from any physical form and transfers it for RPA where the rest of the processing occurs, thus making the process far more efficient than manual methods.
- Faster Credit Card Processing- Banks process credit cards within hours using RPA which used to take days with traditional methods. Proper data of transactions can be maintained and better evaluations of credit scores can also be done.
- Faster Mortgage Loan- Even a minor error can impede loan processing. RPA can accelerate the process by avoiding unnecessary errors and implementing proper checks which would reduce the processing time to minutes from days.
- Vigilant Fraud Detection- RPA tracks all transactions that may give out a red alert and recognises any fraud transaction pattern in real-time. This brings a considerable reduction in response time and can block and prevent fraud to a great extent.
- More Credible KYC Process- Know Your Customer (KYC) is mandatory for banks for each customer. KYC process compliance alone costs banks more than $384 million per year(Thomson Reuters). RPA can reduce this along with the time the customer would have to wait for a response.
- Data Report Automation- RPA helps generate reports without any error for stakeholders providing data in many formats. They can create a report by auto-filling the available report format with minimal errors and time.
- Easier Account Closure Process- Customers benefit Faster account closing process. This increases their affinity to the bank.
How is Automation Boosting The US Banking Sector?
Valued at USD 167.1 million in 2018 and anticipated to register a CAGR of 31.3% from 2019 to 2025, the global robotic process automation in the BFSI market size was rather unprecedented.
The advent of advanced technologies and a need for increased productivity of operations in the United States of America lead to the entire BFSI sector in the country to significantly boost its demand for RPA. Since the USA has a rich inventory of legacy systems, the incorporation and advancements of RPA were upstanding. This increased the agility and precision of processing.
Even casual users can check their accounts and set up automatic payments of their bills. Even KYC verification and other numerous functions are also possible in a much easier fashion. Numerous other back-end and front-end processes are automated using RPA.
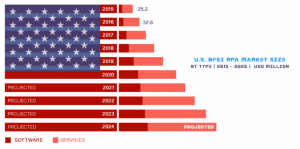
Source: www.grandviewresearch.com
In the US a considerable level of RPA has been integrated as alternatives for services such as BPO, robot deployments at the enterprise level, etc which otherwise would have been tremendously expensive. Further, the initiative eliminated repetitive and time expending tasks which have been automated. It reduces the cost of such tasks from 25% to 50% and the TAT to a minimal amount.
Artificial Intelligence and RPA funding spent in the banking and finance industry in the United States increased at 82.9% during 2018 to reach US$ 696.3 million. Over the forecast period (2019–2025), spend on AI is expected to reach a CAGR of 28.4%, increasing from US$ 1,094.9 million in 2019 to reach US$ 6,289.1 million by 2025.
USA and Canada dominated the market for RPA in 2018 in the Banking industry. On average, a U.S. bank with USD 10+ billion assets spends approximately USD 50 million per year on CDD, KYC compliance, and onboarding. The increased expense of KYC and AML compliance coupled with the steep fines over regulatory scrutiny are necessitating financial institutions to adopt new technology and automation. This prevents identity theft, financial fraud, terrorist funding, and money laundering.
The USA and Canada are set to dominate the financial market with RPAs for at least the next half of the decade. Banks are targeting to preserve patrons and reduce customer attrition and RPA helps them as the customer data is strategized and used to contact the customer as required. North America valued at $376.2 billion in 2019 is projected to reach $721.3 billion by 2027. The digital payment segment being the largest service segment in the industry is expected to head the market with the increase in banking products and sales through online portals is also a helpful factor. In 2019 the digital sales sector was valued at $609.4 billion.
Top Banks in US Taking Automation to The Next Level
- JPMorgan Chase
The biggest bank in the US, JPMorgan Chase, always stood in the first place when it came to technology investments. A tremendous investment of $11.4 billion in AI technology by the bank proves its enthusiasm for innovation and far-sighted outlook(Source-JPMorgan Chase Annual report 2019). The Bank uses it for improving their databases, search optimization, and Contract Intelligence (COiN)- a Machine Learning technology that uses chatbot systems to build vast databases of legal documents in a short time. - Bank of America
They primarily focus on fraud detection, trading functions, and chatbots. The Bank’s AI-enabled chatbot named Erica(Introduced in late 2017) understands texts and speeches. It not only acts as an inquiry bot but advises the user on suitable financial decisions he could take. Erica approximates 6 million users/customers as of March 2019. The $35 billion lender has invested in the past ten years more than $1 billion in mobile banking which is the simplest area of automation for customers. Their own study revealed that mobile customers have increased to 10% annually. - CitiBank
With an agenda to avoid money laundering and fraud actions, the bank is heavily investing in automation in general and AI technology in particular. They even partnered with Feedzai(2016) for detecting fraudulent transactions. They recognize patterns of multiple transactions from multiple locations where the customer usually doesn’t travel to. The bank has a global network of tech giants that take part in its 6 Citi Global Innovation Labs. With multiple advances in automation and technology, $600 million is expected to be saved per year by the bank. - Wells Fargo
Their chatbot system primarily focuses on clarifying the queries of customers without consuming too much time or requiring physical presence. They also developed a mobile app through predictive analytics. It alerts the customers on issues like exceeded bill payments, etc. It even guides the user with their travel plan and to buy flight tickets. In the year 2019 alone Wells Fargo had nearly spent $9 billion on technology and automation.
Conclusion
The global adoption of a digital era is inevitable making Banking and Automation essentially complementary to each other. The automation of the banking industry with the use of Traditional Automation, RPA, and AI have led developed nations like the USA to develop a more efficient and sustainable economy.
The reason why banks and financial institutions swiftly adopted IT is that their operations, when executed manually, consume immense time and effort from their employees as well as making them perform routine duties and actions, and in the process, missing the opportunity to move up the value pyramid. Automation produces a standardized audit trail, ensuring the right people have access to the proper systems and making sure that financial institutions stick to industry standards while decreasing expenses involved.
The necessity of Automation in Banking is precedented. Its implementation has been mostly successful, but as all things do, it too requires betterment. At the end of the day, the adoption of Automation for banks and other financial industries is a matter of ‘When’ rather than If’.
About Signzy
Signzy is a market-leading platform redefining the speed, accuracy, and experience of how financial institutions are onboarding customers and businesses – using the digital medium. The company’s award-winning no-code GO platform delivers seamless, end-to-end, and multi-channel onboarding journeys while offering customizable workflows. In addition, it gives these players access to an aggregated marketplace of 240+ bespoke APIs that can be easily added to any workflow with simple widgets.
Signzy is enabling ten million+ end customer and business onboarding every month at a success rate of 99% while reducing the speed to market from 6 months to 3-4 weeks. It works with over 240+ FIs globally, including the 4 largest banks in India, a Top 3 acquiring Bank in the US, and has a robust global partnership with Mastercard and Microsoft. The company’s product team is based out of Bengaluru and has a strong presence in Mumbai, New York, and Dubai.
Visit www.signzy.com for more information about us.
You can reach out to our team at reachout@signzy.com
Written By:
Signzy
Written by an insightful Signzian intent on learning and sharing knowledge.