How we built a modern, state of the art OCR pipeline — PreciousDory
October 6, 2018
9 minutes read
Finally I am very happy writing this blog after a long wait. As the title suggests PreciousDory is a modern optical character recognition (OCR) engine which performs better than the engines from tech giants like Google, Microsoft, Abby in KYC use cases. We feel now it is time to tell the world how we built this strong OCR pipeline over the last couple of years.
We at Signzy are trying to build a global digital trust system. We solve various fascinating problems related to AI and computer vision. Of them, text extraction from document images was one of the critical problem we had to solve. In the initial phase of our journey we were using traditional rule based OCR pipeline to extract text data from document images. Those OCR engines were not that efficient to compete with global competitors. So In an urge to stay competitive with the global market we took an ambitious decision to build an inhouse modern OCR pipeline. We wanted to build an OCR engine which will surpass the global leaders in that segment.
The herculean challenge was out and our AI team accepted it with a bliss. We know building a production ready OCR engine and achieving best in class results is not an easy task. But we are a bunch of gallant people in our AI team. When we started researching about the problem we found very few resources to help us out. And we also stumbled upon the below meme ?

If You Can’t Measure It, You Can’t Improve It
The first task our team did was to create a test dataset that would represent all the real world scenarios we could encounter. The scenarios includes varying viewpoints, illumination, deformation, occlusion, background clutter, etc. Below are some samples of our test dataset.

Sample test data
When you have a big problem to solve, break it down into smaller ones
We spent a quite a lot of time in literature study trying to break the problem into sub-problem so that our individual team members could start working on it. We ended with the below macro level architecture.
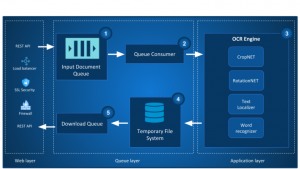
Macro level architecture
After coming up with the basic architectures our team started exploring the individual entities. Our core OCR engine comprises of 4 key components.
- CropNET
- RotationNET
- Text localizer
- Word classifier
CropNET
This is the first step in the OCR pipeline. The input documents for our engine will have a lot of background noise. We needed an algorithm to exactly crop out the region of interest so that the job gets easier in the subsequent steps. In the initial phase we tried out lot of traditional image processing techniques like edge detection, color matching, Hough lines etc. None of them could withstand our test data. Then we took the deep learning approach. The idea was to build a regression model to predict the four edges of the document to be processed. The train data for this model was the ground truth containing the four coordinates of the document. We implemented a custom shallow architecture for predicting the outputs. We achieved good performance from the model.

RotationNET
This is the second stage in the pipeline. After cropping, the next problem to solve is rotation. It was estimated that 5% of the production documents would be rotated in arbitrary angles. But for the OCR pipeline to work properly the document should be at zero degree. To tackle the problem we built a classification model which predicts the angle of document. There are 360 classes corresponding to each degree of rotation. The challenge was in creating the training data. As we had only few real world samples for training each class, we had to build a custom exhaustive pipeline for preparing synthetic training data which closely matches with real world data. Upon training , we achieved impressive results from the model.

Text localizer
The third stage is localizing the text areas. This is the most challenging problem to solve. Given a document the algorithm must be able to localize the text regions for further processing. We knew building this algorithm from scratch is a mammoth task. We benchmarked various open source text detection models on our test datasets.
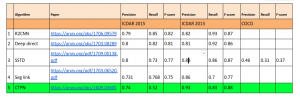
Text localization — Benchmark
After rigorous testing we decided to go with CTPN. Connectionist Text Proposal Network (CTPN) accurately localizes text lines in natural image. It detects a text line in a sequence of fine-scale text proposals directly in convolutional feature maps. It was developed with a vertical anchor mechanism that jointly predicts location and text/non-text score of each fixed-width proposal, considerably improving localization accuracy. The sequential proposals are naturally connected by a recurrent neural network, which is seamlessly incorporated into the convolutional network, resulting in an end-to-end trainable model. This allows the CTPN to explore rich context information of image, making it powerful to detect extremely ambiguous text.

Word classifier
This is the final stage and the most critical step in the OCR engine. This is the step where most of our efforts and time went into. After localizing the text regions in the document, the region of interest was cropped out of the document. Now the final challenge is predict the text from this. Upon rigorous literature study we arrived with two approaches for solving this problem.
- Character level classification
- Word level classification
Character level
This is one of the traditional approach. In this method the bounding box of individual characters are estimated and from them the characters are cropped out and presented for classification. Now what we have in hand is a MNIST kind of dataset. Building a classifier for this type of task is tried and tested method. But the real challenge in this approach was in building the character level bounding box predictor. Normal segmentation methods failed to perform on our test dataset. We thought of developing a FRCNN like object detection pipeline for localizing the individual characters. But creating the training data for this method was a tedious task and involves a lot of manual work. So we ended up dropping this method.
Word level classifier
This method is based on deep learning. Here we pass the full text localized region into a end to end pipeline and directly get the predicted text. The cropped text region is passed into a CNN for spatial feature extraction and then passed on to RNN for extracting temporal features. We are using CTC loss to train the architecture. CTC loss solves two problems: 1. You can train the network from pairs (Image, Text) without having to specify at which position a character occurs using the CTC loss. 2. You don’t have to postprocess the output, as a CTC decoder transforms the NN output into the final text.
The training data for this pipeline is cropped word image regions and their corresponding ground truth text. Since a large amount of training data was required to make the model converge, we made a separate data creation pipeline. In this we first get the cropped word regions from the document, secondly we feed it into third party OCR engine to get the corresponding text. We used this data to benchmark it against manually created human data. The manual data was again verified by a 2 stage human process to make sure the labels are right.
We achieved impressive results with the model. A sample output from the model.
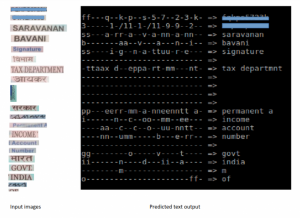
Time for results
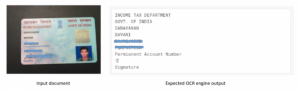
At Last we combined all the four key components into a single end to end pipeline. The algorithm now takes an input image of a document and gives the corresponding OCR text as output. Below is a sample input and output of a document.
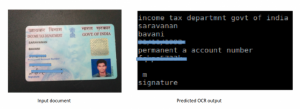
Now the engine was ready to face our quality analysis team for validation. They benchmarked the pipeline against popular global third party OCR engines on our custom validation set. Below are the test results for certain important documents we were handling.
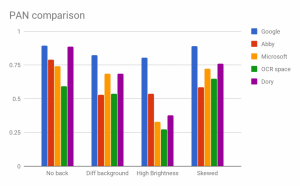
We tested our OCR engine against other top engines on different scenarios. It includes cases with no background, different background, high brightness and low brightness. The results shows that we are able to perform better than the popular known OCR engines in most scenarios.
Productionzation
The pipeline was built now and tested. But still it was not ready to face the real world. Some of the challenges in productionsing the system are listed below.
- Our OCR engine was using GPU for inference. But since we wanted the solution to be used by our clients without any change in their infrastructure, we removed all the GPU dependencies and rewrote the code to run in CPU.
- To serve large number of requests more efficiently we builded a queueing mechanism.
- For easier integration with existing client infrastructures, we provided the solution as a REST API
- Finally the whole pipeline was containerized to ease the deployment at enterprises.
Summary
Thus a mammoth of task building a modern OCR pipeline was accomplished. A special thanks to my team members Nishant and Harshit for making this project successful. One of the key take away from the project was that if you have an exciting problem and a passionate team in hand, you could make the impossible possible. And I could not explain a lot of steps in details since I had to keep the blog short. Do write to me if you have any queries.
About Signzy
Signzy is a market-leading platform redefining the speed, accuracy, and experience of how financial institutions are onboarding customers and businesses – using the digital medium. The company’s award-winning no-code GO platform delivers seamless, end-to-end, and multi-channel onboarding journeys while offering customizable workflows. In addition, it gives these players access to an aggregated marketplace of 240+ bespoke APIs that can be easily added to any workflow with simple widgets.
Signzy is enabling ten million+ end customer and business onboarding every month at a success rate of 99% while reducing the speed to market from 6 months to 3-4 weeks. It works with over 240+ FIs globally, including the 4 largest banks in India, a Top 3 acquiring Bank in the US, and has a robust global partnership with Mastercard and Microsoft. The company’s product team is based out of Bengaluru and has a strong presence in Mumbai, New York, and Dubai.
Visit www.signzy.com for more information about us.
You can reach out to our team at reachout@signzy.com
Written By:
Signzy
Written by an insightful Signzian intent on learning and sharing knowledge.












